Poisson-Based Inference for Perturbation Models in Adaptive Spelling Training
G.-M. Baschera, M. GrossInternational Journal of Artificial Intelligence in Education, vol. 20, no. 4, 2010, pp. 333-360
Abstract
We present an inference algorithm for perturbation models based on Poisson regression. The algorithm is designed to handle unclassified input with multiple errors described by independent mal-rules. This knowledge representation provides an intelligent tutoring system with local and global information about a student, such as error classification (local) and prediction of further performance (global). The inference algorithm has been employed in a student model for spelling with a detailed set of letter and phoneme based mal-rules. The local and global information about the student allows for appropriate remediation actions to adapt to their needs. The error classification, student model prediction and the efficacy of the adapted remediation actions have been validated on the data of two large-scale user studies. The enhancement of the spelling training based on the novel student model resulted a significant increase in the student learning performance.Overview
A central feature of an intelligent tutoring system (ITS) is the ability to adapt to student needs, based on an abstract representation of the student, called student model. In this paper we present a novel approach for estimating the student’s proficiency in a perturbation model with independent error production rules, called mal-rules. In contrast to previous work, our method can handle student inputs with multiple, unclassified errors, i.e., errors which cannot be unambiguously related to one of the independent malrules. The method was implemented in a student model for spelling training, where errors can be described by several independent mal-rules, such as visual confusion of letters, auditory confusion of phonemes, or typing errors. Figure 1 illustrates four mal-rules for phoneme-grapheme matching errors.
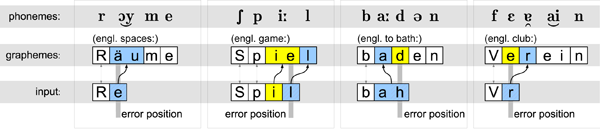
We regard errors as randomly occurring events, which are best described by a Poisson
distribution. We do not assume the student attributes to be either in a learned or unlearned state. Mal-rules
describe the difficulties in spelling and divide them into different categories. They, however, do not
represent a concept of spelling, that just can be acquired and once mastery is reached, only slipping or
other rules will cause subsequent errors of the same type. E.g., visual and auditory confusions of
letters in dyslexic children cannot simply be comprehended and removed. Similarly, the irregularities
in the phoneme-grapheme mapping inhibit a sudden mastery of the phoneme-grapheme matching
process. Therefore, we represent the strengths and weaknesses in spelling by the error rates on malrules
for every individual student. For the estimation of these error rates we propose a Poisson
regression. The employment of a linear link function in the Poisson regression assures the independence of the factors.
The proposed method emerged from insights gained during a first user study of Dybuster.
In collaboration with elementary school teachers and psychologist, we identified the
demand for information on two levels to adapt spelling training appropriately to student’s needs:
- Local information: error localization and classification to enable adequate remediation on erroneous inputs.
- Global information: student knowledge representation to allow for optimized word selection based on further spelling performance prediction on the entire word database, and for feedback to human tutors on students’ strengths and weaknesses.
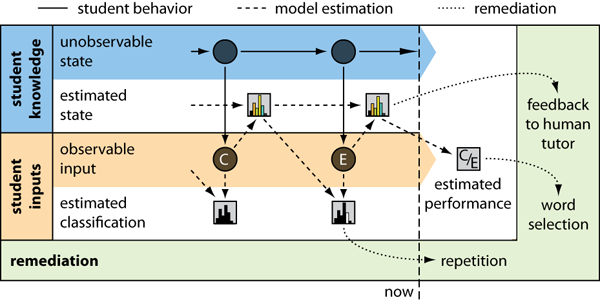
The student model described in this paper is designed to provide both, local and global information about an individual student. To render the model adaptable to different student strengths and weaknesses, we developed an error taxonomy for isolated word spelling, and defined corresponding mal-rules. During the spelling training, the student is represented by the error rates of each mal-rule. After each observed input of the student, the estimation of the unobservable knowledge state is updated (see Figure 2) using our Poisson-based inference algorithm. Based on these estimated error rates, the model enables a classification of subsequent erroneous inputs (local information), and a prediction of further spelling performance (global information). The information provided by the student model allows for appropriate remediation actions of the learning environment and human tutors.
Results
The presented mal-rules and the associated inference algorithm provide global and local information about student inputs. In a first step, we show an example of error classification and prediction for three selected students to illustrate the influence of different student characteristics. Following, prediction and classification are validated based on the student data of the first user study. Additionally we present our analysis of forgetting, which was used to optimize the remediation actions. Finally, the results of the second study, utilizing the developed student model, are presented. We investigate the gain in learning progress, induced by the student model and the corresponding remediation actions.
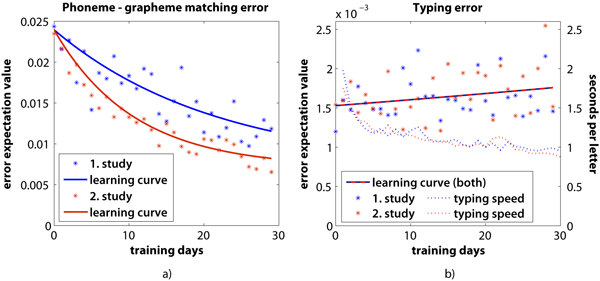
Figure 3 illustrates the learning curves for students of the first and second user study. One can clearly observe a gain in learning progress of the very relevant PGM errors. The analysis of typing errors, which are not in focus of the Dyslexia training, does not yield any significant differences between the two studies.

