An FPGA-based processing pipeline for high-definition stereo video
P. Greisen, S. Heinzle, M. Gross, A. BurgEURASIP Journal on Image and Video Processing, 2011, pp. 18
Abstract
This paper presents a real-time processing platform for high-definition stereo video. The system is capable to process stereo video streams at resolutions up to 1920 × 1080 at 30 frames per second (1080p30). In the hybrid FPGA-GPU-CPU system, a high-density FPGA is used not only to perform the low-level image processing tasks such as color interpolation and cross-image color correction, but also to carry out radial undistortion, image rectification, and disparity estimation. We show how the corresponding algorithms can be implemented very efficiently in programmable hardware, relieving the GPU from the burden of these tasks. Our FPGA implementation results are compared with corresponding GPU implementations and with other implementations reported in the literature.Overview
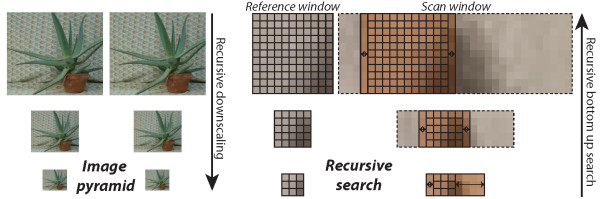
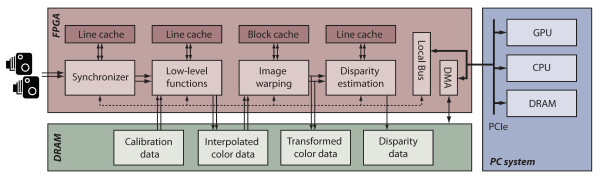
In this work, a processing platform for high-definition stereo video is presented. The platform employs FPGAs to perform low-level image processing, image warping, and disparity estimation in real-time and in full HD resolution. We describe the corresponding hardware-efficient algorithms, the essential components of the associated hardware architecture, and the required caching mechanisms that enable the processing of high-definition video streams. The FPGA is integrated into a heterogeneous PC platform that also comprises a GPU and a CPU for further processing. We argue that this mapping of the stream processing onto the FPGA is advantageous since the CPU and GPU resources can in turn be spent on higher-level operations. Such operations can include control algorithms for automatic camera systems or memory intensive algorithms with a more global scope such as segmentation, which often are less suited for FPGA-based stream processing. To this end, we provide reference numbers to illustrate the GPU resources freed for other tasks by the FPGA implementation. Finally, we provide a comparison of our hardware implementation to other state-of-the-art implementations of the core algorithms and the corresponding limitations.
Results

The proposed camera architecture has been evaluated using an experimental beam-splitter rig with two synchronized cameras, with a maximum resolution of 2048 × 2048 pixels at 30 fps. The host platform uses a six-core CPU paired with an NVIDIA GTX480 GPU. The FPGA design is deployed on a PCI Express board fitted with one ALTERA Stratix III with two DDR2 RAMs and a PCIe 8× interface. The design is implemented in VHDL, and a fixed-point golden model (implemented in MATLAB) is used as functional reference. The stereo video stream is captured on two Camera Link interfaces, processed in the FPGA, and finally transferred to the main memory of the PC using DMA. Figure 2 illustrates the camera system.
FPGA Performance
The entire stereo pipeline fits easily into an ALTERA Stratix III (EP3SL340) FPGA. The system is running at 130 MHz and is able to process stereo full-HD at 30 fps (1080p30) video in real-time. The PCIe interface to the PC and the Camera Link interface currently limit the system to scale to higher resolutions and/or frame rates. The FPGA design itself currently supports stereo full-HD at 60 fps (1080p60); higher numbers can be reached by using more hardware resources for depth estimation and further DDR2 controller optimization for the rectification. The latencies of the pre-processing and disparity estimation units are only a couple of lines, the latency of the PCI transfer is one frame (double buffering), and the latency of the rectification is also one frame. The rectification latency could be reduced when assuming that the transformations are small and then start the read-out when the frame is still being processed; however, the present implementation does not support this operation.
Comparison to GPU
The main parts from the stereo pipeline, depth estimation and image warping, have also been implemented on the GPU for comparison. Due to the massive amount of caching and memory bandwidth of modern GPUs, rectification does not pose a challenge to the GPU. However, the hierarchical depth estimation requires approximately 190 ms per frame, which is an order of magnitude slower than our FPGA implementation. For this comparison, the same number of parameters has been chosen as for the FPGA implementation. One of the main advantages over a GPU implementation is the parallelism of the FPGA architecture: all different stages are computed in parallel, while the GPU performs all intermediate stages in sequence. Furthermore, memory transfers constitute a considerable overhead for the GPU implementation. Note that these data transfers are not necessary in our stream processing-based FPGA implementation.

